這幾天我會陸續和大家介紹 Transformer 模型的結構細節。老實說這個模型的重要性真的不容小覷,它幾乎可以說是現在 AI 世界的核心。不誇張地說只要你搞懂了 Transformer,基本上就掌握了現今大多數主流 AI 模型的運作邏輯。過去那些模型(像是 RNN、LSTM)當然也有它們的貢獻,不過你不需要太執著於它們的細節,因為 Transformer 的出現,某種程度上已經統一了這個領域的主流架構。
所,為了讓大家能更扎實地理解這套系統,我會把整個 Transformer 拆解成幾個章節來慢慢講,每一部分都會盡量用清楚、直白的方式來說明,讓你不用被艱澀的數學或名詞卡住也能理解核心概念。
今天我們就從 Transformer 裡的一個關鍵模組Encoder開始談,可以說Encoder 是整個架構的基石。如果你能搞清楚 Encoder 的邏輯和它是怎麼處理資訊的,後面在看 Decoder 或更複雜的應用(像是 GPT 或 BERT)時就會順很多。所以這篇我會一步步拆解 Encoder 的基本組成、每個模組的功能,還有它們背後的設計理念,希望能幫助你真正理解這個影響深遠的系統到底是怎麼運作的。
Transformer 是一種很有意思的深度學習模型架構,核心是所謂的注意力機制(Attention Mechanism。這個架構最早是 2017 年由 Vaswani 等人在一篇叫《Attention is All You Need》的論文中提出的。雖然一開始是專門為自然語言處理(像是翻譯、對話生成)設計的,但後來也慢慢被用在其他領域,比如電腦視覺,甚至現在很多最強的 AI 模型,幾乎都是靠這個架構做出來的。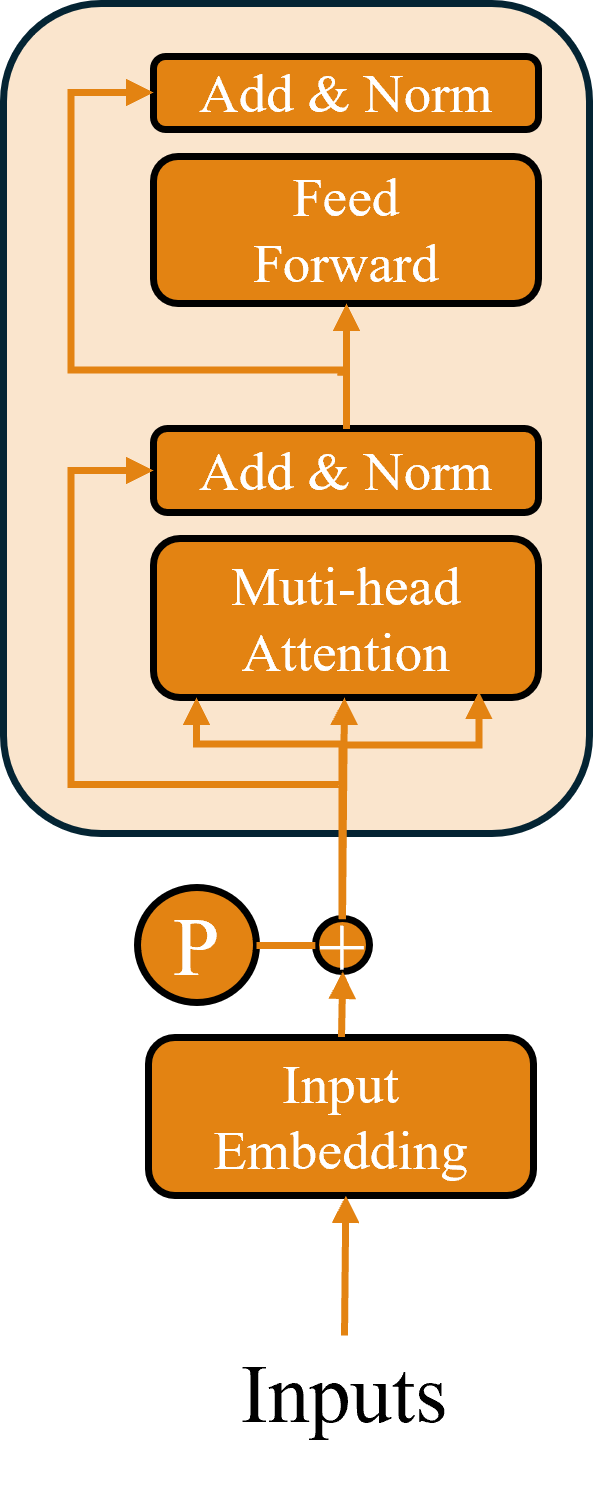
Transformer 最厲害的一點就是它處理「序列資料」的效率特別高,尤其是面對很長的句子或段落時,表現依然穩定。那接下來我們可以先來看看它的 Encoder,也就是整個模型裡負責讀懂輸入資料的部分,到底是怎麼運作的。
傳統的時間序列模型像是 RNN,本身就具備遞迴結構,所以它會自然而然保留輸入資料的順序,也就是前後文的關聯。但 Transformer 完全不是這樣設計的,它靠的是平行運算,意思就是它在處理輸入時,根本不知道每個字是排在第幾個。因此為了讓 Transformer 也能理解順序,就需要額外的機制來補上這一塊資訊。
因此我們就會需要 Positional Encoding(位置編碼),它的做法是把每個詞在句子裡的位置,用一組數學方式編碼進詞向量裡。這個編碼會跟原本的embedding加在一起送進模型。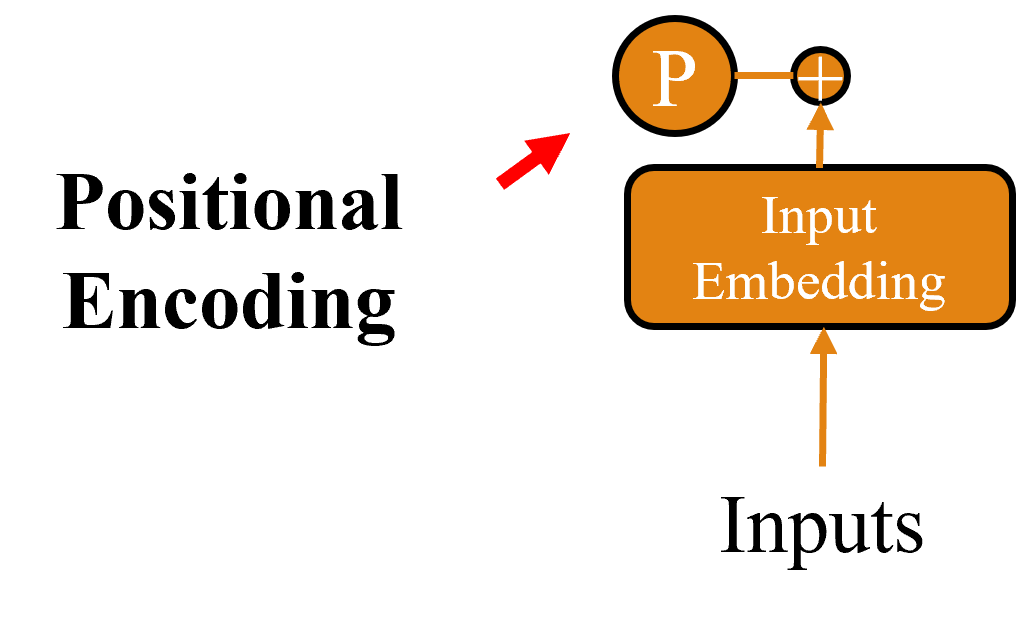
而這個位置資訊的編碼方式,是靠正弦(sin)和餘弦(cos)函數來實現的,而其原因很簡單,因為這兩個函數的波動有週期性,可以用來表示變化的節奏,在偶數編號的維度用 sin 函數來表示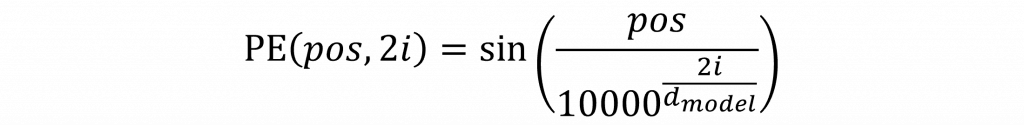
奇數編號的維度用 cos 函數來表示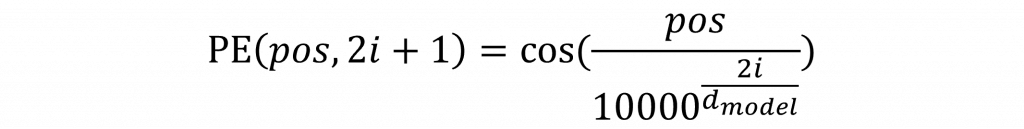
公式中的 pos 表示詞在整個句子中的位置,而 i 是詞向量的第幾個維度,d_model 是整個詞向量的總維度,其中當 i 越大,分母中的值也會越大,這會讓 sin/cos 的變化變得比較慢。這種設計會讓不同的維度以不同的頻率在震盪,進而讓模型能更精細地感受到每個詞在句子中所處的相對位置。
在公式裡那個看起來有點突兀的 10000,其實不是隨便挑的數字,它是一個縮放因子(scaling factor),目的是讓不同維度的變化頻率有所區隔。舉個簡單的比喻你可以把這整個 Positional Encoding 想像成一個「頻率混音器」,每個維度像是一條獨立的聲音軌,頻率高低不同但混在一起可以幫助模型聽出句子中每個詞的位置。
具體來說低維度的變化比較劇烈(頻率高),高維度則變化得比較慢(頻率低),這種設計能讓模型從不同角度感受到詞序的影響,就像同一個場景用廣角與長焦鏡頭各拍一張照片一樣,提供多層次的空間訊息。而在程式碼中我們可以這樣撰寫
import torch
import torch.nn as nn
import math
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
# 建立 (max_len, d_model) 大小的位置編碼矩陣
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # shape: (max_len, 1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() *
(-math.log(10000.0) / d_model))
# 偶數維度用 sin,奇數維度用 cos
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 增加 batch 維度方便加到輸入上
pe = pe.unsqueeze(0) # shape: (1, max_len, d_model)
# 註冊 buffer,不會更新參數但會一起移到 GPU
self.register_buffer('pe', pe)
def forward(self, x):
"""
x shape: (batch_size, seq_len, d_model)
"""
seq_len = x.size(1)
# 加上對應長度的 positional encoding
return x + self.pe[:, :seq_len, :]
再來講講 max_len 的角色,這個參數其實是告訴模型你最多會處理多長的句子。在初始化位置編碼時,我們會先建立一個尺寸為 (max_len, d_model) 的矩陣,意思是我先準備好所有從第 0 個詞到第 max_len-1 個詞的所有位置編碼。不管你之後輸入的句子多長,我都有辦法從這個表裡撈出對應的那一段位置資訊來加進去。如果你的模型只會處理短句子,比如最多 128 個 token,那就可以把 max_len 設成 128。相對地,如果你在處理長篇文本(像是摘要、小說等),那就要把 max_len 設得大一點,避免在 forward 時出現超出範圍的錯誤。
還有一點比較進階但很重要的register_buffer,這不是普通的變數註冊,而是 PyTorch 中用來儲存不參與訓練但又需要跟著模型移動(像是轉到 GPU 上)」的資料。也就是說我們並不希望這個位置編碼在訓練過程中被改動,但又不能把它當成一般常數,因為它得跟著模型搬到 CUDA 裡才能正確運作。register_buffer 就是解這個問題的標準做法。
在 Transformer 架構裡最核心的技術就是 Self-Attention(自注意力機制),這個機制有點像是模型在讀一段文字時會自己去看整個句子,判斷哪些詞跟現在這個詞有關係,然後把注意力放在那些比較重要的詞上。也因為這樣,Transformer 才能慢慢取代像 Seq2Seq 那種比較傳統、需要 Encoder 跟 Decoder 不斷互動的架構,變得又快又準。
講到自注意力,會牽扯到三種向量查詢(Query, Q)、鍵(Key, K)、值(Value, V),每個輸入的詞(也就是 Token)都會被轉換成這三種向量。怎麼轉?其實就是把原本的詞向量(通常是 embedding)乘上三個不同的權重矩陣,分別是W_Q、W_K、W_V,你可以想像成是先經過一層 embedding,再用三個不同的線性層(nn.Linear)做運算。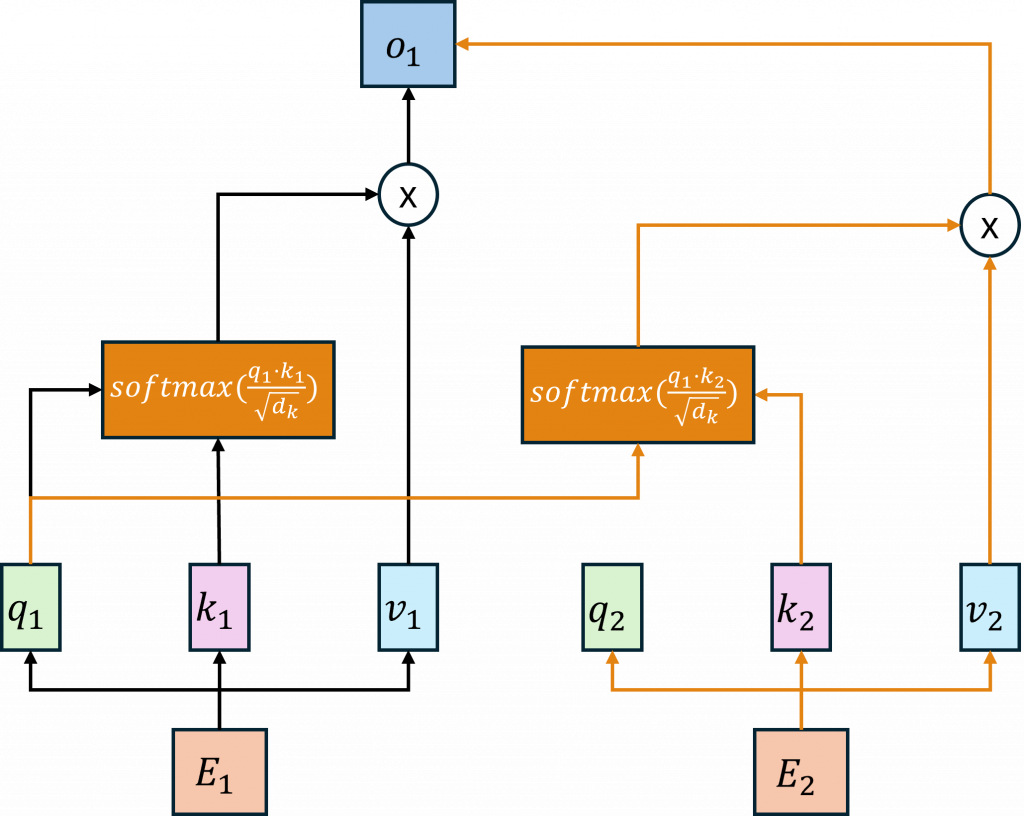
而在上圖中的動作簡單來說,Q 就是拿來問問題的,K 是拿來比對的,而 V 是答案內容。接下來的流程是這樣:我們會拿查詢向量 Q 去跟所有詞的鍵向量 K 做點積,算出一個數值這個數值代表兩個詞之間的關聯程度,稱為 Attention Score。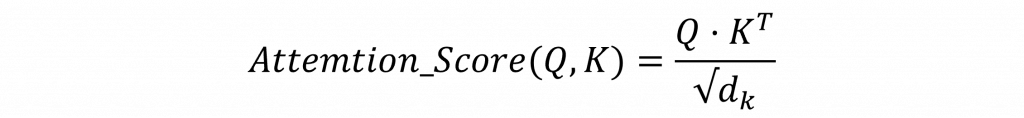
然後我們會把這些 Score 丟進 Softmax,把它們變成一組機率,這組機率就是所謂的 Attention Weights,也就是我現在該多關注哪個詞的分數。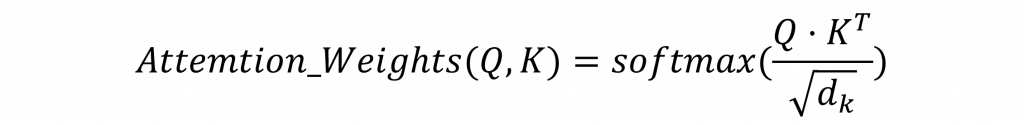
最後我們用這些機率去加權每個詞的值向量 V,加總後就得到這次注意力機制的輸出。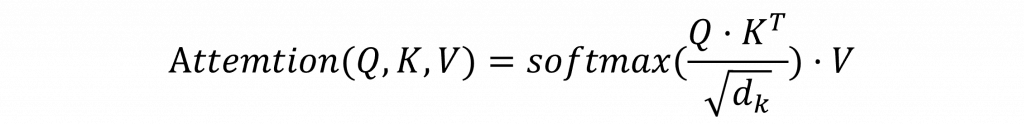
其中 √𝑑 這是 Q 和 K 向量的維度大小開根號(也就是詞向量空間)。為什麼要除這個?因為當向量維度太高時,Q 和 K 的點積結果可能會變得非常大,導致 Softmax 結果變得很極端,模型就學不好了。所以我們會用這個值來做縮放,把結果拉回合理的範圍。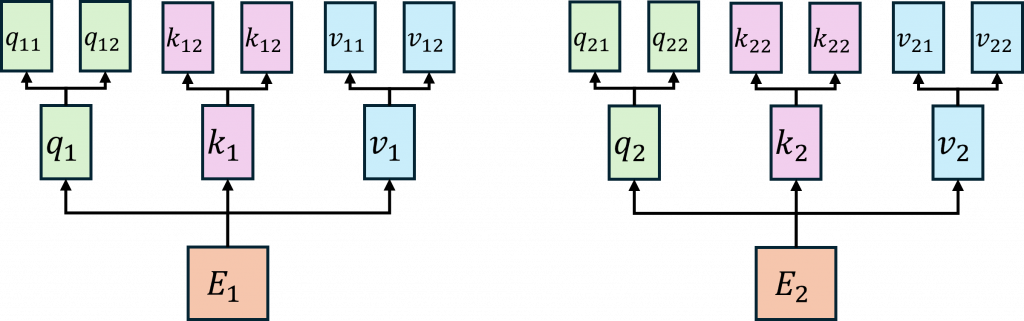
講到這裡其實 Transformer 真正厲害的地方在於它用的是Multi-Head Self-Attention(多頭自注意力機制),不是只有一個頭在做注意力運算,而是會把 Q、K、V 拆成好幾組,每組都各自計算注意力,最後再把這些結果合起來,也就是以下的公式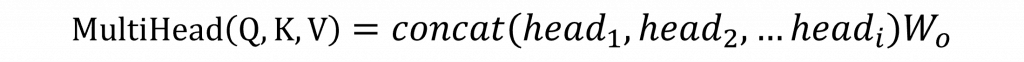
每個 attention head 本質上就是一次 Attention(Q, K, V) 的運算,而為什麼要用多個 head 呢?簡單來說,這樣做的好處是,每個頭可以專心」輸入句子的不同面向。像是有的 head 可能比較關注句子的語法結構,有的可能在抓語氣或情緒,還有的也許專注在主題相關的詞,這種設計讓模型能從多個角度來理解整個句子。
不過這邊有個小細節要注意,我們在計算 Attention 分數的時候有一個除以 √d 的操作,這個 d代表的是每個 head 的向量維度,既然我們把整體的 d_model 切成多個 head,那每個 head 的向量空間就要平均分配,這樣 scale 才會算得對。所以在程式碼裡,可以看到我們是把整個詞向量的維度平均分成多份:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, nhead, dropout=0.1):
super(MultiHeadAttention, self).__init__()
assert d_model % nhead == 0
self.d_model = d_model
self.nhead = nhead
self.d_k = d_model // nhead
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
self.scale = math.sqrt(self.d_k)
而在前向傳播時這邊不使用 torch.cat 來合併,而是用了 view + transpose,目的是把整個向量拆成多個子空間,好讓每個 head 處理屬於自己的那一份資料。如果使用cat會需要使用迴圈,而選擇 view 和 transpose 只是比較快的做法。
def forward(self, query, key, value, mask=None, key_padding_mask=None):
batch_size = query.size(0)
seq_len_q = query.size(1)
seq_len_k = key.size(1)
# 將 Q/K/V 映射後 reshape 成 (batch_size, nhead, seq_len, d_k)
Q = self.w_q(query).view(batch_size, seq_len_q, self.nhead, self.d_k).transpose(1, 2)
K = self.w_k(key).view(batch_size, seq_len_k, self.nhead, self.d_k).transpose(1, 2)
V = self.w_v(value).view(batch_size, seq_len_k, self.nhead, self.d_k).transpose(1, 2)
# 計算注意力分數
scores = torch.matmul(Q, K.transpose(-2, -1)) / self.scale
# 套用 attention mask
if mask is not None:
# 確保 mask 的形狀正確
if mask.dim() == 2:
mask = mask.unsqueeze(0).unsqueeze(0) # (1, 1, seq_len, seq_len)
elif mask.dim() == 3:
mask = mask.unsqueeze(1) # (batch_size, 1, seq_len, seq_len)
scores = scores.masked_fill(mask, float('-inf'))
# 套用 padding mask
if key_padding_mask is not None:
# key_padding_mask: (batch_size, seq_len_k)
# 需要擴展為 (batch_size, 1, 1, seq_len_k)
key_padding_mask = key_padding_mask.unsqueeze(1).unsqueeze(2)
scores = scores.masked_fill(key_padding_mask, float('-inf'))
# 計算注意力權重
attn_weights = F.softmax(scores, dim=-1)
attn_weights = self.dropout(attn_weights)
# 計算 weighted sum 後 reshape 回原始形狀
context = torch.matmul(attn_weights, V)
context = context.transpose(1, 2).contiguous().view(
batch_size, seq_len_q, self.d_model
)
# 最終輸出線性變換
output = self.w_o(context)
return output
而在 Attention 分數計算中,我們其實是把每個詞對其他所有詞都看一遍,但我們不希望模型「偷看」,這時就要用到 mask,舉個例子:
<pad> token,但這些其實沒有意義,也要遮起來,不然模型可能會把注意力浪費在這些 padding 上。這兩種情況分別會用到:
-inf,這樣在做 softmax 的時候,那些位置就會變成 0,模型自然就不會理它們。當我們在講 Transformer 的架構時,除了大家常提到的 Attention,其實還有一個很重要但常被忽略的部分前饋神經網路(FeedForward Network, FFN)。
這一層的設計其實不複雜,就像是兩個線性層夾一個非線性函數,你可以把它想像成每個詞在經過 Attention 和其他詞聊天溝通後,還需要回過頭來自己想一想,把剛剛收到的資訊消化一下、重新組織,提煉出更有代表性的內部特徵。
import torch
import torch.nn as nn
import torch.nn.functional as F
class FeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1, activation='gelu'):
super(FeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, d_ff)
self.linear2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
if activation == 'relu':
self.activation = F.relu
elif activation == 'gelu':
self.activation = F.gelu
else:
raise ValueError('Unsupported activation function: {}'.format(activation))
def forward(self, x):
return self.linear2(self.dropout(self.activation(self.linear1(x))))
簡單來說,它就是:
這種搭配其實就像是你開完會(Attention),回到座位還是要自己整理筆記、做功課(FFN),這樣整體的表現才會更強。
另一個值得注意的地方是,在 Transformer 裡面引入了所謂的 Layer Normalization。簡單講它的作用就是幫每一層的輸入做個標準化處理,讓輸出的結果更穩定,這樣整個模型在訓練時就比較容易收斂,也能跑得更快、更穩定。雖然它聽起來有點像 Batch Normalization,但其實兩者做法不太一樣 Layer Norm 是針對每個樣本自己做正規化,而不是像 Batch Norm 那樣,是一整批資料一起處理。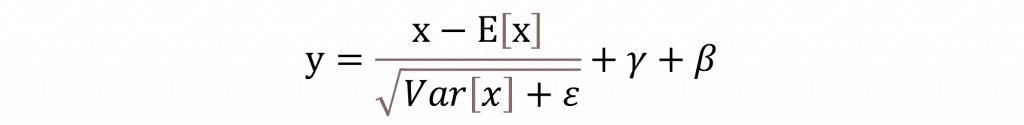
你可能有注意到公式裡會出現個 ε這個小符號,它的主要功能其實就是防止在運算過程中除以零這種尷尬情況發生。所以它通常會被設得非常小,基本上就是個保險機制,確保計算的穩定性。而 γ則是控制輸出要放大多少的參數,它其實會在每一層都被調整,讓模型可以學會不同特徵的重要性。至於 β,它的角色是偏移量,讓模型可以微調輸出的整體分佈,讓結果更貼近真實數據的樣貌。
現在我們來把這些零件組起來看一下。你會發現在 Encoder 的程式碼裡有兩次出現 output + layer['dropout'](src2) 這樣的寫法,這其實就是大家常提到的 Skip Connection(跳躍連接),也有人叫它 Residual Connection(殘差連接)。
那這東西到底有什麼用?你可以想像一下,神經網路一層一層往下走,訊息每經過一層就會被改寫一次,但有時候改著改著,原本的重要訊息可能就不見了或者變得模糊了。Skip Connection 的概念就是不要把原始訊息整個丟掉,讓它繞個小路走旁邊,再回來跟處理後的結果合在一起,這樣做有兩個好處:
class Encoder(nn.Module):
def __init__(self, d_model, nhead, d_ff, num_layers, dropout=0.1, norm=None):
super(Encoder, self).__init__()
self.layers = nn.ModuleList([
nn.ModuleDict({
'self_attn': MultiHeadAttention(d_model, nhead, dropout),
'feed_forward': FeedForward(d_model, d_ff, dropout),
'norm1': nn.LayerNorm(d_model),
'norm2': nn.LayerNorm(d_model),
'dropout': nn.Dropout(dropout)
}) for _ in range(num_layers)
])
self.num_layers = num_layers
self.norm = norm
def forward(self, src, mask=None, src_key_padding_mask=None):
output = src
for layer in self.layers:
# 自注意力 + Skip Connection + LayerNorm
src2 = layer['self_attn'](output, output, output, mask, src_key_padding_mask)
output = layer['norm1'](output + layer['dropout'](src2))
# 前饋網路 + Skip Connection + LayerNorm
src2 = layer['feed_forward'](output)
output = layer['norm2'](output + layer['dropout'](src2))
if self.norm is not None:
output = self.norm(output)
return output
整個流程就是這樣src2 是注意力學出來的新訊息,而 output 是進來這一層的輸入,兩個加在一起,再丟進 LayerNorm,這樣就可以把新的資訊跟原本的訊息自然地融合起來。這個設計真的很關鍵,可以說是 Transformer 成功的秘密武器之一,因為這樣不只穩定訓練,還不太容易出現梯度爆炸或訓練發散的問題。
明天我們會來聊聊 Transformer Encoder的經典代表BERT,這個模型從推出以來一直是自然語言處理領域的主力選手,至今仍被廣泛應用在各種任務上。明天會聚焦在它的整體架構、與原始 Transformer 的差異,以及它為什麼能夠這麼強大。而明天不會有數學而是基於今天內容的模型講解,目標是讓你真正理解 BERT 究竟做對了什麼,才讓它能紅這麼久、用得這麼廣。


 iThome鐵人賽
iThome鐵人賽